
При выполнении критически важных рабочих процессов вам необходимо знать свои ограничения. Поэтому недавно мы протестировали различные развертывания n8n – имитируя интенсивный трафик и максимально используя ресурсы, чтобы увидеть, какие настройки окажутся лучшими.
Независимо от того, занимаетесь ли вы подработкой или управляете инжинирингом в многонациональной организации, стресс-тестирование имеет большое значение для предотвращения простоев, узких мест и невыполненных обещаний. Этот эталонный блог и video покажет вам, как далеко может зайти n8n и где он начнет разваливаться!
Тренировка для вашего рабочего процесса
Мы провели стресс-тестирование n8n на двух типах экземпляров AWS – C5.large и C5.4xlarge – используя как сингл n8n, так и Queue режимы (многопоточная архитектура на основе очередей). Мы использовали K6 для нагрузочного тестирования, Beszel для мониторинга ресурсов в реальном времени и собственные рабочие процессы сравнительного анализа n8n для автоматического запуска каждого сценария стресс-тестирования.
В этом рабочем процессе использовалась электронная таблица для итерации по различным уровням виртуальных пользователей (ВУ), запуска каждого теста и записи результатов по мере его выполнения. После регистрации данных мы превратили их в график, на котором были показаны ключевые показатели эффективности. Кроме того, в режиме реального времени мы могли видеть, насколько хорошо система работала при различных нагрузках – насколько быстро она реагировала, насколько надежно она работала и где она начала трескаться.
Вот как мы это настроили:
The C5.большой AWS пример включал:
1 vCPUs
2 Threads
4 GB RAM
10 Gbps bandwidth
Когда мы расширились до C5.4x большой, мы добавили 16 виртуальных процессоров + 32 ГБ оперативной памяти.
Мы запустили три критических сценария сравнительного анализа:
Одиночный вебхук: один поток запускается повторно
Мультивебхук: 10 рабочих процессов, запускаемых параллельно
Двоичные данные: загрузка и обработка больших файлов
Каждый тест масштабировался от 3 до 200 виртуальных пользователей для измерения:
Запросы в секунду
Среднее время ответа
Частота отказов под нагрузкой
Если вы хотите организовать собственное стресс-тестирование, в конце этого блога мы включили все инструменты, необходимые для начала работы, включая n8n Benchmark Scripts.
Одиночный вебхук
Мы начали с малого, с одного вебхука. Это имитировало отправку запроса веб-перехватчика на сервер n8n и отправку ответа о том, что мы получили этот вызов веб-перехватчика. Это был всего лишь один рабочий процесс и одна конечная точка, постепенно наращивающая трафик, чтобы увидеть, насколько далеко можно продвинуть один экземпляр n8n.
Используя экземпляр C5.large AWS, развертывание n8n Single mode на удивление хорошо справилось с нагрузкой, как вы можете видеть из сравнительной таблицы ниже. Хотя этот экземпляр вмещал до 100 VU, как только мы достигли 200 VU, мы достигли потолка того, с чем может справиться однопоточная установка, со временем отклика до 12 секунд и частотой отказов 1%.
Когда мы включили режим очереди, более масштабируемую архитектуру n8n, которая отделяет прием вебхуков от выполнения рабочего процесса, производительность подскочила до 72 запросов в секунду, задержка упала менее чем на три секунды, и система обработала 200 виртуальных пользователей с нулевым количеством сбоев.
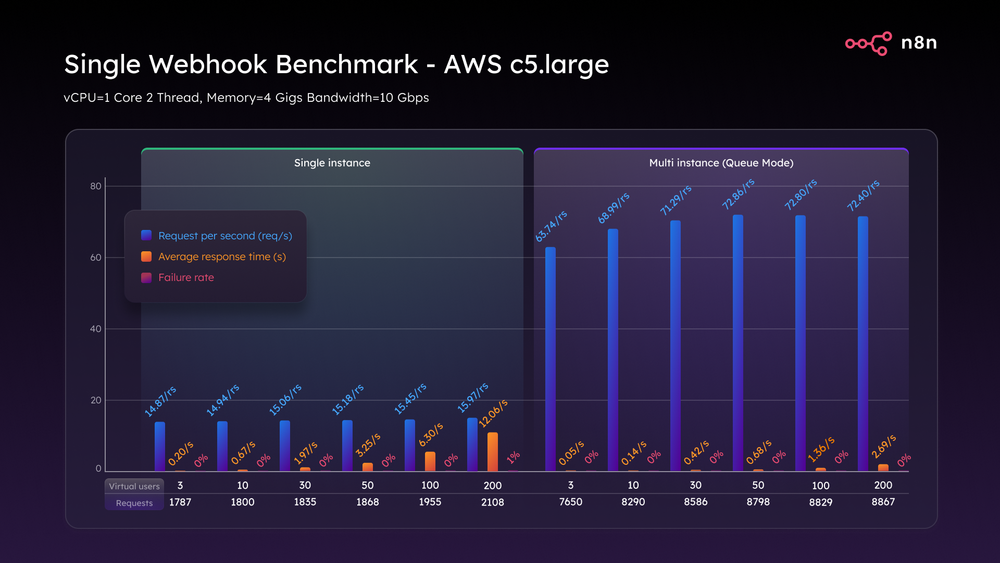
Тест одного вебхука AWS c5.large
При масштабировании до C5.4xlarge (16 виртуальных ЦП, 32 ГБ ОЗУ) мы увидели впечатляющие результаты. В одиночном режиме пропускная способность немного выросла до 16,2 запросов в секунду при умеренном улучшении задержки.
Но именно режим очереди действительно затмил всех. Мы достигли стабильных 162 запросов в секунду и поддерживали их при полной нагрузке 200 VU, с задержкой менее 1,2 секунды и нулевым количеством сбоев. Это означает 10-кратный прирост пропускной способности просто за счет вертикального масштабирования и выбора правильной архитектуры.
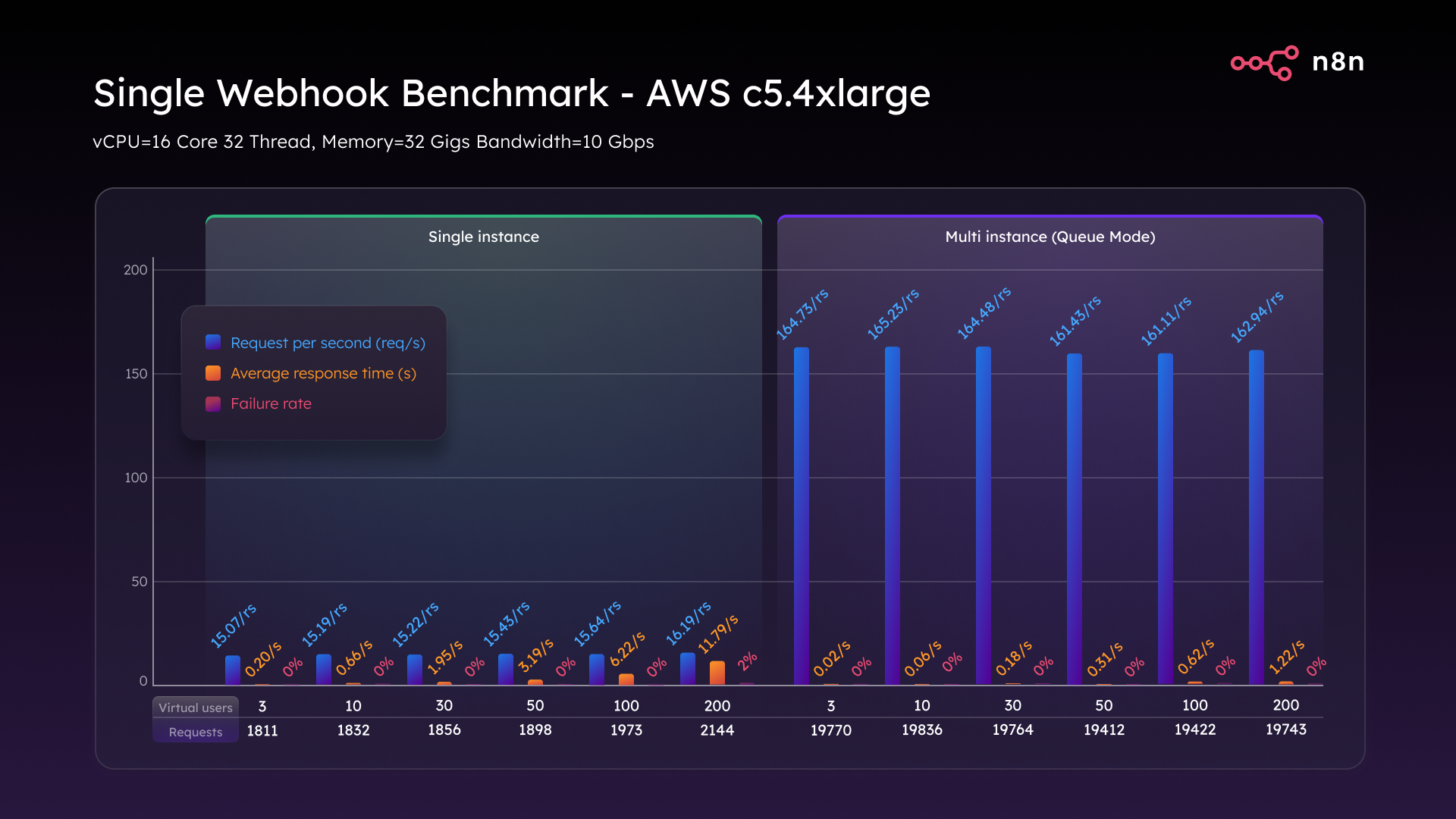
Тест одного вебхука AWS c5.4xlarge
Несколько веб-хуков
Для следующего теста мы хотели смоделировать многозадачность корпоративного уровня, чтобы лучше отразить реальные развертывания n8n поэтому мы настроили 10 отдельных рабочих процессов, каждый из которых запускается своим собственным вебхуком.
На C5.large в одиночном режиме, производительность быстро упала. При 50 VU время отклика превысило 14 секунд, а частота отказов составила 11%. При 100 VU задержка достигла 24 секунд, а частота отказов составила 21%. А при 200 VU частота отказов достигла 38%, а время отклика увеличилось до 34 секунд – по сути, расплавление.
Переход в режим очереди изменил игру. Он стабильно обрабатывал 74 запроса в секунду от трех до 200 VU с задержкой в приемлемых пределах и частотой отказов 0%. То же самое оборудование, совершенно другой результат.
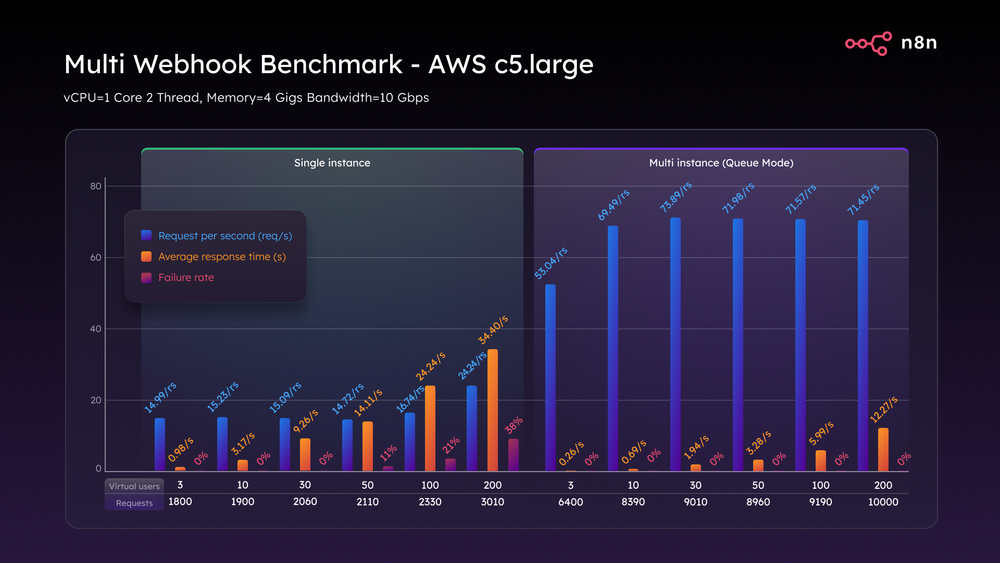
Тест мультивебхука AWS c5.large
И снова C5.4xlarge вывел ситуацию на новый уровень. В одиночном режиме он достиг пика в 23 запроса в секунду с частотой отказов 31%. Но в режиме очереди мы выполняли и поддерживали 162 запроса в секунду при всех нагрузках, без сбоев. Даже при максимальном стрессе задержка оставалась около 5,8 секунды. Масштабная многозадачность требует больше мускулов, и режим очереди абсолютно обеспечивает это.
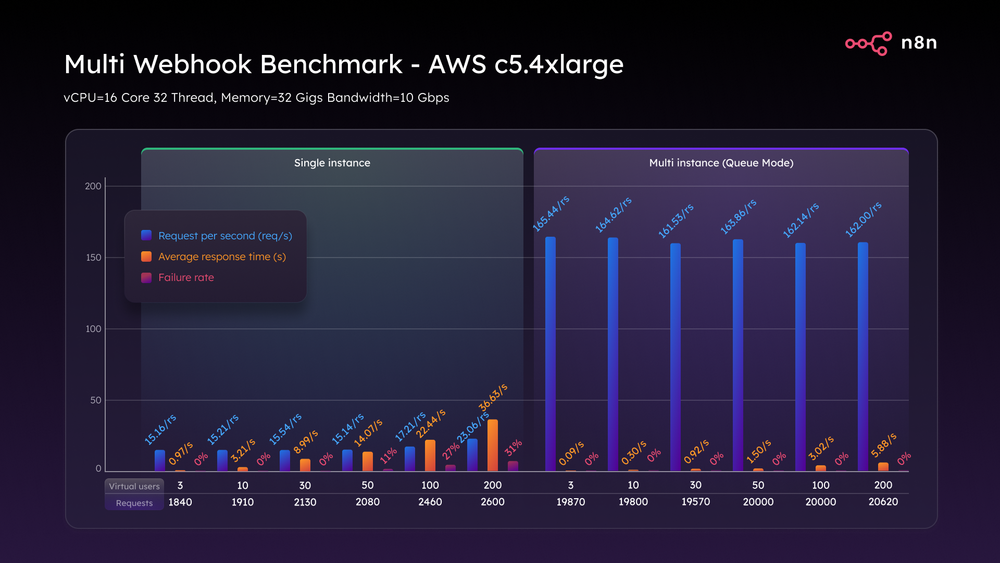
Тест Multi WebHook AWS c5.4xlarge
Загрузка двоичных файлов
Наконец, мы хотели протестировать как можно более ресурсоемкие и ресурсоемкие задачи, поэтому мы настроили бенчмарк двоичных данных с рабочими процессами, которые обрабатывают большие объемы загружаемых файлов, таких как изображения, PDF-файлы и медиафайлы.
На C5.large в одиночном режиме трещины появились рано. Всего при трех виртуальных пользователях мы обрабатывали всего три запроса в секунду. При 200 VU время ответа резко возросло, и 74% запросов были отклонены. Это не просто замедление, это полный сбой в работе.
Режим очереди обеспечивал немного большую устойчивость, задерживая поломку. Однако к 200 ВУ он также вышел из строя с 87% отказов и неполной полезной нагрузкой.
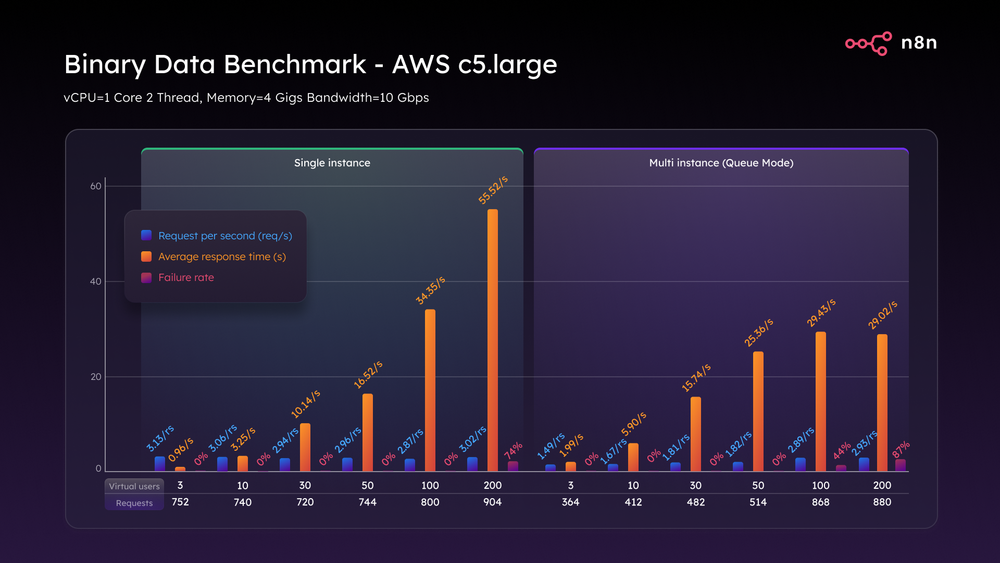
Тест двоичных данных AWS c5.large
Затем мы обратились к C5.4xlarge. Благодаря этому более крупному экземпляру в однорежимном режиме мы достигли 4,6 запросов в секунду, сократили время ответа на треть и снизили частоту отказов с 74% до всего лишь 11%. Значительно улучшено, но не идеально.
Затем в режиме очереди мы достигли пика в 5,2 запроса в секунду и, что особенно важно, удерживали частоту отказов 0% на протяжении всего теста. Каждый большой файл был успешно получен, обработан и на него был дан ответ. Этот тест ясно показал – дело не только в архитектуре. Рабочие процессы с большим объемом двоичного кода требуют серьезной пропускной способности ЦП, ОЗУ и диска.
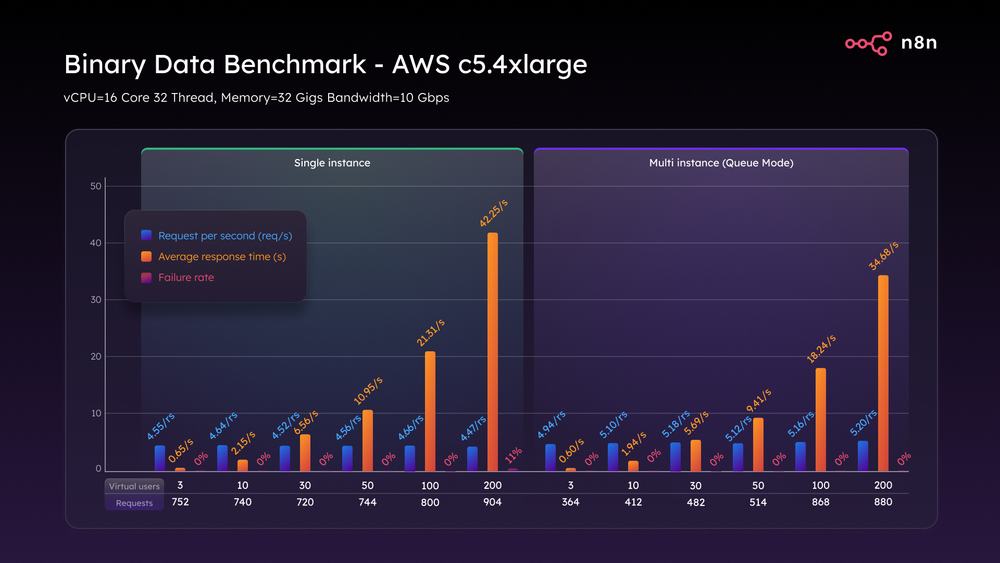
Тест двоичных данных AWS c5.4xlarge
Ключевые выводы
Так о чем же нам сказали все эти тесты?
Режим очереди не является необязательным. Это первый шаг к реальной масштабируемости. Даже на оборудовании начального уровня он значительно повышает производительность при минимальной настройке.
Аппаратное обеспечение имеет значение. Обновление до C5.4xlarge более чем удваивает пропускную способность, сокращает задержку вдвое и полностью устраняет частоту отказов.
Двоичные данные ломают все —если вы не готовы. Для управления всем этим вам понадобится больше оперативной памяти, более быстрый диск, общее хранилище, такое как S3, и параллельные рабочие процессы.
Если вы создаете автоматизацию для внутренних команд, внутренних систем или клиентских приложений, не ждите возникновения узких мест, которые заставят вас выполнить обновление. Планируйте масштаб с самого начала. Используйте режим очереди, чтобы отделить прием от обработки, масштабируйте горизонтально с работниками для одновременной обработки и определяйте размер оборудования в соответствии с вашей рабочей нагрузкой. Простые потоки требуют меньше, но двоичные данные и многозадачность требуют больше. n8n создан для масштабирования, но, как и любому двигателю, ему нужно правильное топливо и правильная траектория, чтобы достичь полной мощности.
Перевод с https://blog.n8n.io/the-n8n-scalability-benchmark/